SEO Crawler
- Crawle bis zu 10.000 Seiten einer Domain
- Crawle auf Wunsch mit ausgeführtem JavaScript (Headless Browser)
- Wenn die Analyse abgeschlossen ist, erhältst du eine E-Mail
- Je nachdem wie schnell die Website antwortet, kann das auch mal ein paar Stunden dauern
- Hier kannst du den Fortschritt sehen
- auch als Whitelabel SEO Tool verfügbar
Der kostenlose SEO Crawler
Ein SEO Crawler oder SEO Spider crawlt eine ganze Website. Das bedeutet, wie eine Suchmaschine findet der Crawler Links und folgt diesen. Je nach Umfang einer Website können so wenige Hundert bis hin zu vielen tausend URLs gefunden werden. Jede dieser URLs wird dann auf diverse Faktoren überprüft. Dies ist derselbe Vorgang den zum Beispiel Google benutzt um Domains zu crawlen und dann in den Index und die Suchergebnisse aufzunehmen. Suchergebnisse basieren auf URLs und nur wenn diese URLs gefunden werden, nicht durch technische Maßnahmen gesperrt sind, intern verlinkt sind und sinnvollen Inhalt haben können sie indexiert werden.
Was macht ein SEO Crawler oder SEO Spider?
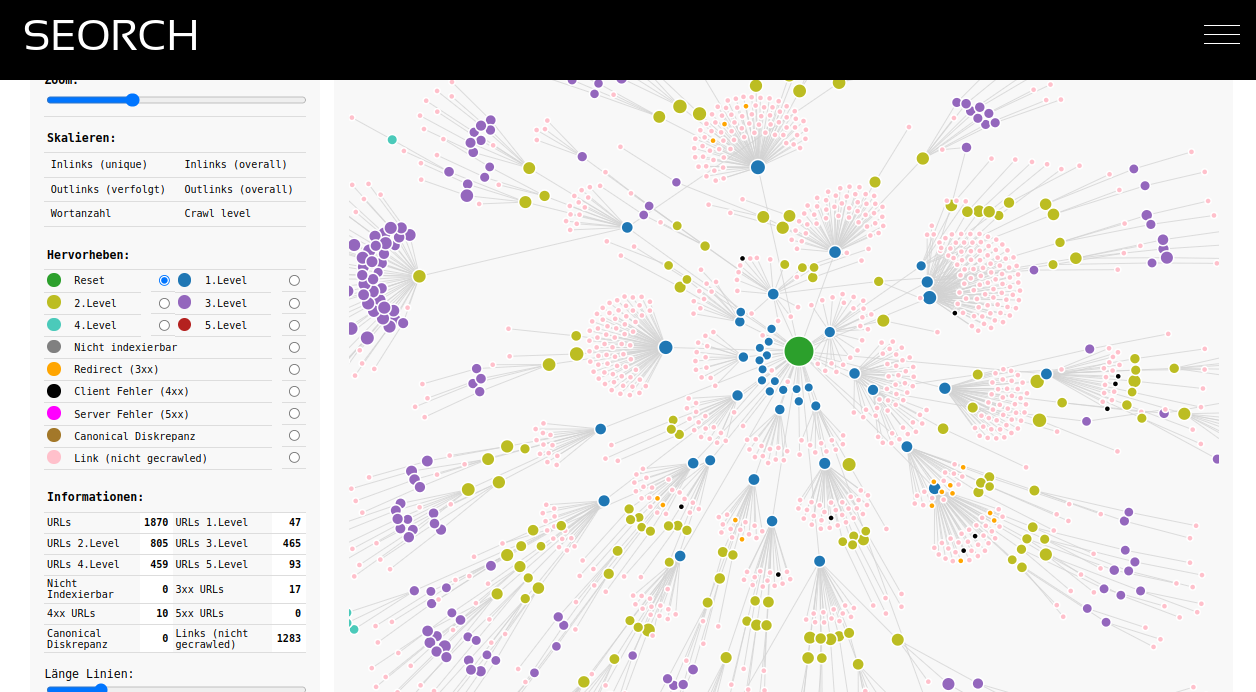
Der SEO Spider emuliert den Crawl einer Suchmaschine. Er versucht also eine Domain mit all ihren Seiten genau so zu interpretieren wie es der Spider einer Suchmaschine tut. Der Unterschied zum Crawl der Suchmaschine ist, dass du das Ergebnis sehen kannst. Also alle Probleme oder technischen Informationen einer Seite werden im Ergebnis des Crawls angezeigt. Dadurch kann man einfach und schnell herausfinden, wo die Suchmaschine ggf. Probleme hat oder ob es zum Beispiel Bereiche einer Domain gibt welche von der Suchmaschine nicht gefunden oder indexiert werden können.
Es gibt dutzende von Gründen warum eine URL nicht gecrawlt werden kann und darum nicht in den Suchergebnissen angezeigt wird. URLs können beispielsweise einen sogenannten "noindex" Tag haben, über die robots.txt gesperrt sein, mit einer Weiterleitung antworteten, einen Canonical Tag auf eine andere URL haben usw. All das kann dir eine SEO Crawler anzeigen. Du kannst diese Fehler beheben oder auch bewusst in kauf nehmen und dann die Seite wieder crawlen und deine Arbeit überprüfen.
Warum solltest du einen SEO Crawler benutzen?
Selbst ein ganz einfaches Wordpress Blog hat (neu installiert) SEO Probleme. Für keine Seite ist eine Meta Description vorhanden. Diese Meta Description wird aber von Suchmaschinen verwendet und deine Seite in den Suchergebnissen anzuzeigen. Nun gibt es hunderte von verschiedenen Content Management Systemen, Webshops oder Frontend Frameworks welche heutzutage eingesetzt werden. Vom technischen SEO Gesichtspunkt betrachtet sind aber nur sehr wenige komplett frei von Fehlern. Ein SEO Crawler findet diese Fehler und sie können behoben werden.
Websites existieren über einen langen Zeitraum und sind Veränderungen unterworfen. Es entstehen neue URLs, alte URLs werden abgeschaltet, ganze Themenbereiche entstehen neu, Redesigns werden gemacht und das CMS bekommt auch ab und zu mal ein Update. Dann arbeiten vielleicht viele Personen an einer Domain und so entstehen viele Altlasten. Durch regelmäßige SEO Crawls kann man aber sicherstellen, dass keine dieser Veränderungen zu Problemen mit Suchmaschinen führt.
Beispielsweise wird die neue Version eines Webshops live gestellt. Da dieser Webshop vorher in der Entwicklungsumgebung getestet wurde, wurde das Crawling des neuen Shops über die robots.txt gesperrt. Wenn man nun nicht regelmäßig crawlt würde das erst auffallen wenn die Rankings aus den Suchmaschinen verschwinden, weil sich z.b. der Googlebot an die robots.txt Regeln hält.
Was prüft ein SEO Crawler?
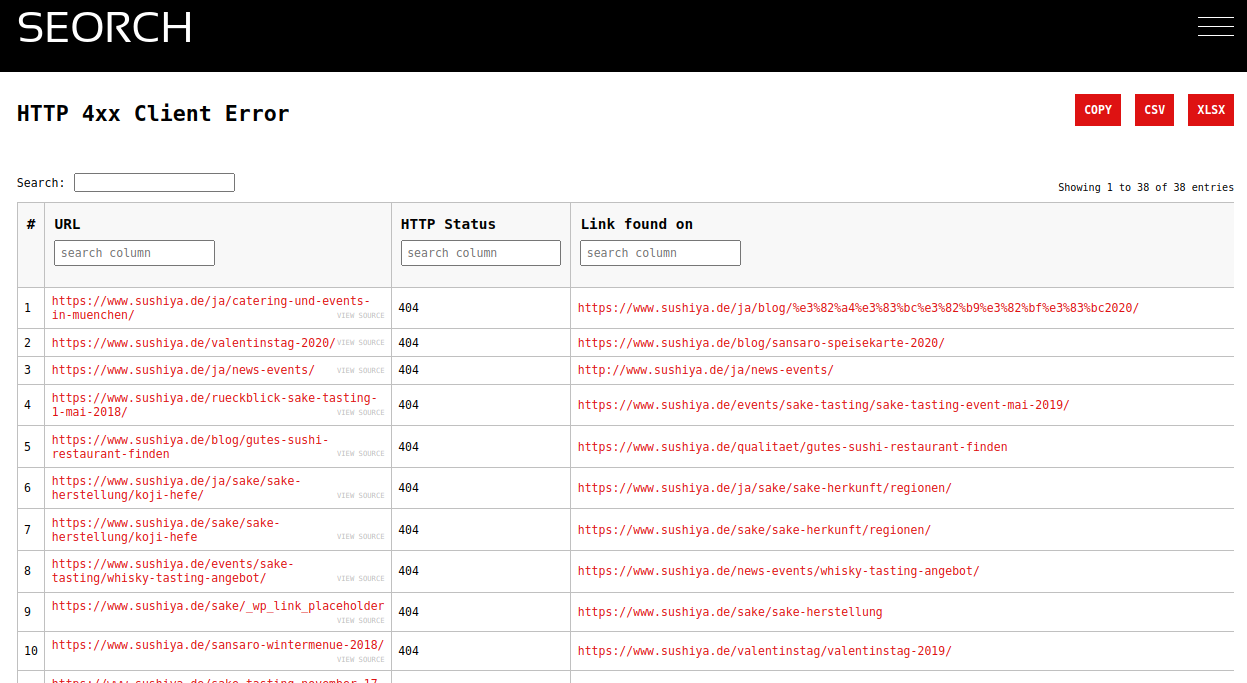
- kaputte Links die z.b. in einem HTTP 404 Statuscode enden
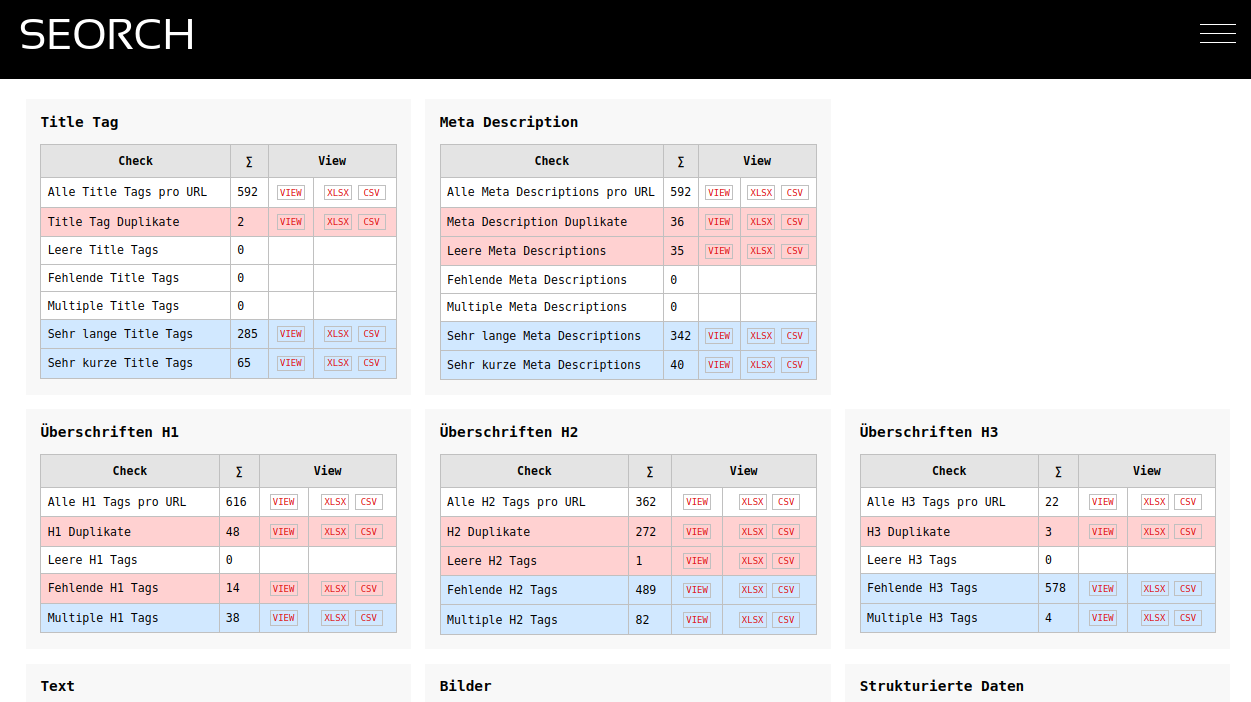
- Title Tags und Meta Descriptions, Duplikate und fehlende und leere Tags
- Weiterleitungen, Server Fehler und Client Fehler
- Meta Robots / X-Robots und robots.txt und deren disallow / noindex Angaben
- Canonical und Hreflang Tags
- XML Sitemaps
- Überschriften und Texte, Duplicate Content
- Bilder, ALT Tags und Bildgrößen
- Strukturierte Daten (Microdata, JSON-LD)
- Interne und externe Links, Linktexte
- URLs, Aufbau von URLs und Fehler in URLs
- Antwortzeiten, Time To First Byte
- und vieles mehr
Was unterscheidet den SEORCH SEO Crawler von Wettbewerbern?
Es gibt eine Vielzahl an SEO Crawlern (Screaming Frog SEO Spider, Audisto, Deepcrawl oder Sitebulb) alle haben gemeinsam, dass man entweder gar keine oder nur sehr wenige Seiten kostenlos crawlen kann. Man muss also ein Abo abschließen oder sich ein Crawl Kontingent kaufen. Das macht für SEO Profis auch durchaus Sinn, aber liegt leider oft außerhalb des Budgets von kleineren Projekten.
Mit dem SEORCH Crawler kannst du bis zu 20.000 URLs kostenlos crawlen. Es gibt keine Einschränkungen und keine Limits. Alle Analysen und Daten kannst du dir online ansehen und auch als CSV oder Excel Datei herunterladen. Durch den kostenlosen Ansatz können die Daten allerdings nicht für immer gespeichert werden. Wenn ein alter Crawl nicht mehr in der Datenbank ist kannst du aber einfach noch einmal crawlen.
Was macht man mit dem Ergebnis des Crawls?
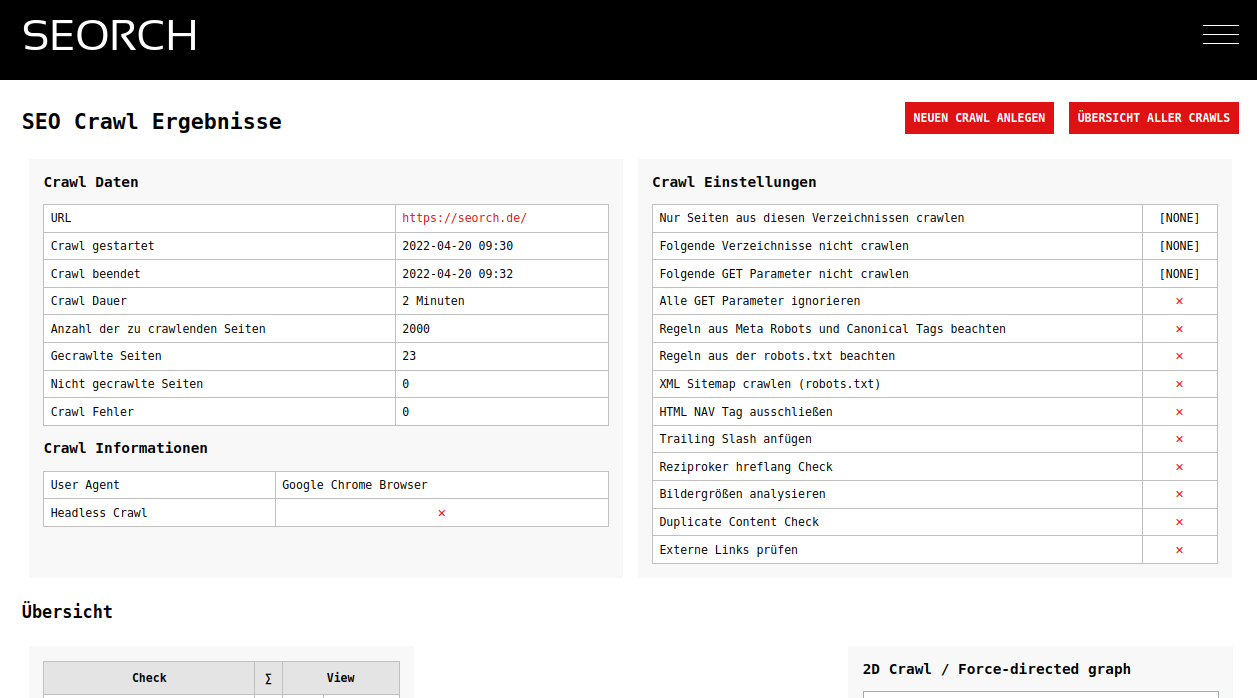
Probleme oder Fehler sind im Ergebnis des Crawls blau und rot hinterlegt und man sollte sich Anfang davon nicht überfordern lassen. Idealerweise nimmt man sich ein Thema vor, lädt das Excel herunter und schaut sich das Problem erst mal auf der Website ein. Beispielsweise sind 404 Fehler recht leicht zu finden und zu korrigieren. Aber auch fehlende Title Tags oder leere Meta Descriptions sind ein guter Startpunkt um die Seite zu optimieren. Weist eine Seite eine hohe Anzahl an Server Fehler auf (HTTP 500) sollte man direkt mit den Entwicklern der Seite sprechen und die Fragen wo die Gründe liegen können.